
직렬화와 역직렬화의 개념
- 직렬화 Serialization
- 객체를 직렬화하여 전송 가능한 형태로 만드는 것
- 역직렬화 Deserialization
- 직렬화된 파일 등을 역으로 직렬화하여 다시 객체의 형태로 만드는 것
직렬화가 필요한 이유
개발 언어를 무엇을 선택하든, 사용하는 데이터의 메모리 구조는 크게 2가지로 나뉜다.
- 값 형식 데이터
- int, float, char 등 값 형식 데이터는 스택에 메모리가 쌓이고 직접 접근이 가능하다.
- 참조 형식 데이터
- 객체와 같은 참조 형식 변수를 선언하면 힙에 메모리가 할당되고, 스택에서는 이 힙 메모리를 참조하는 구조로 되어 있다.
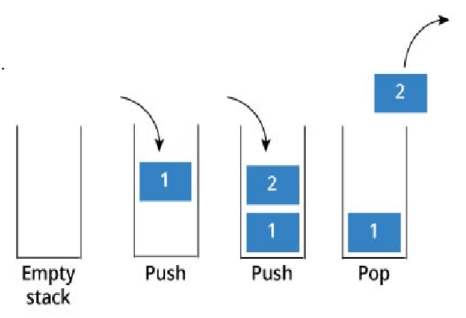
스택에는 수직으로 값이 쌓이고 들어온 순서대로 나가는 것이 아니라 스택에서 제일 최근 값이 먼저 나간다.
위 두 가지 데이터 중에서 디스크에 저장하거나 통신할 때는 값 형식 데이터만 사용할 수 있다. 참조 형식 데이터는 실제 데이터 값이 아닌 힙에 할당되어 있는 메모리 번지 주소를 가지고 있기 때문이다.
- 참조 형식 데이터를 사용할 수 없는 이유
예를 들어, 객체 A를 만들고 주소 값이 0x00045523라고 가정하자. 그리고 이 값을 파일에 포함하여 저장했다고 해보자. 이후 프로그램을 종료하고 다시 실행해서 주소 값 0x00045523을 가져오더라도 기존 A 객체의 데이터를 가져올 수 없다. 프로그램이 종료되면 기존에 할당되었던 메모리(0x00045523)는 해제되고 없어지기 때문이다.
네트워크 통신 또한 마찬가지이다. 각 PC마다 사용하고 있는 메모리 공간 주소는 전혀 다르다. 그러므로 내가 다른 PC로 전송한 A 객체 데이터(0x00045523)는 무의미하다. 이 데이터를 받은 PC의 메모리 주소 0x00045523에는 전혀 다른 값이 존재하기 때문이다.
- 그래서 직렬화를 왜 하는가?
디스크에 저장하거나 통신할 때 값 형식 데이터만 가능하고, 참조 형식 데이터는 안 된다는 것을 이해하였다. 그러면 직렬화는 도대체 왜 필요한 것인가?
직렬화를 하게 되면 각 주소 값이 가지는 데이터를 전부 끌어 모아서 값 형식 데이터로 변환해 준다. 직렬화가 된 데이터는 언어에 따라서 텍스트 또는 바이너리 등의 형태가 되는데, 이러한 형태가 되었을 때 저장하거나 통신할 때 파싱이 가능한 유의미한 데이터가 된다.
즉, 직렬화를 하는 이유는 사용하고 있는 데이터를 파일 저장 혹은 데이터 통신에서 파싱할 수 있는 유의미한 데이터를 만들기 위함이다.
데이터 직렬화의 종류
- CSV, XML, JSON 직렬화
- 사람이 읽을 수 있는 형태.
- 저장 공간의 효율성이 떨어지고, 파싱하는 시간이 오래 걸림.
- 데이터의 양이 적을 때 주로 사용함.
- 최근에는 JSON 형태로 통해 데이터를 직렬화를 많이 함.
- 모든 시스템에서 사용이 가능함.
- Binary 직렬화
- 사람이 읽을 수 없는 형태.
- 저장 공간을 효율적으로 사용할 수 있고, 파싱하는 시간이 빠름.
- 데이터의 양이 많을 때 주로 사용함.
- 모든 시스템에서 사용이 가능함.
- ex) 프로토콜 버퍼, Apache Avro 등
- Java 직렬화
- Java 시스템 간의 데이터 교환이 필요할 때 사용함.
'🌏CS' 카테고리의 다른 글
| [Linux] 💻내가 보려고 정리하는 리눅스 명령어들 (0) | 2022.10.20 |
|---|---|
| [CS] 절차적 프로그래밍 vs 객체지향 프로그래밍 (0) | 2022.08.22 |