참고한 강의
논리적 데이터 모델링
: ERD를 관계형 데이터베이스 모델에 어울리게 변환하는 과정
=> Mapping rule을 중점으로 보면 됨
논리적 데이터 모델링
- 개념적 모델링이 잘 되어있다면 기계적으로 하면되기 때문에 상대적으로 쉬움!
- 뽑아낸 개념을 관계형 패러다임에 어울리는 이상적인 모습으로 정리해 주는 것
- Mapping Rule
- erd로 표현한 내용을 관계형 데이터베이스에 맞는 형식으로 전환할때 사용하는 방법론
- Entity -> Table
- Attribute -> column
- Relation ->PK,FK
일대일 관계

- 외래키 설정
- 의존하는 테이블(혼자서 잘 못지냄) : 자식 (외래키) => 휴면저자 (외래키 : author_id)
- 의존 되는 테이블(혼자서 잘지냄) : 부모 => 저자
일대다 관계

- 외래키 설정
- n 에게 주면 됨.
다대다 관계


👉 외래키가 여러개인 경우 JOIN 불가능

- 매핑 테이블 추가 ->erd에 추가 + 스키마에 추가
- 두개의 테이블이 결합 시에 의미있는 정보 등을 추가 가능
- 스키마에만 추가하면 됨 (사진)

- erd에 반영? (할필요가 없음)

- 스키마에만 추가하면 됨
논리적데이터모델링2 : 정규화 Nomalization
- 정규화 Nomalization
- 평범한 표를 관계형 데이터 베이스에 어울리는 표로 만드는 공정

- 1정규화 -> 2 정규화 -> 3 정규화 .. 이런 식으로 순차적으로 바꾸는 식
제 1 정규화
Atomic columns 각행의 각 칼럼의 값들이 원자적이어야 한다.
- Atomic : 어떤 것이 더이상 쪼개질 수 없는 성질
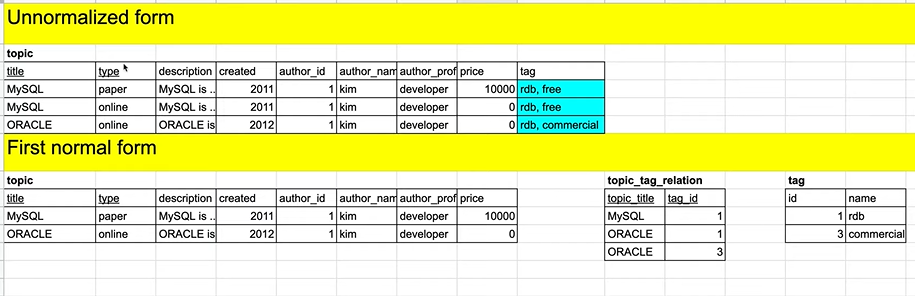
1. 원자적이지 않은 칼럼 찾기 => 하나의 컬럼안에 여러개(하나초과)의 값이 들어가 있음) => tag
=> 하나의 값으로 찾기도 어렵고 (select where)
정렬하기도 어렵고 (order by)
join하기도 어려움

(1) 같은 행을 반복해서 여러개의 값을 따로 쓴다 -> 정보의 중복 발생

(2) 태그1 태그2로 나눠서 해준다 -> 태그가 추가될수록 전체 테이블의 컬럼이 추가됨 / null이 생김 (유연하지않음)

🚩 표를 쪼개기!
- 토픽과 태그는 (n:m) =>매핑 테이블 필요!
- 토픽의 PK 와 태그의 PK를 같이 쓰므로써 원자적으로 함
제 2정규화
No partial dependencies 부분 종속성이 없어야 한다! (부분종속성제거)
- 표의 기본키중에 중복키가 없어야 한다! (없으면 안해도됨)
- 부분적으로 종속되는 컬럼만 모으고 전체종속되는 정보들만 모으기

1. 부분 종속성에 따른 중복 발생

🚩 중복되는 부분을 따로 표로 만듦.
제 3 정규화
No transitive dependencies 이행적 종속성 제거

- 이행적 종속성
- author_id는 title에 따라 달라짐 -> author_id는 title에종속
- author_name과 author_profile은 author_id에 종속됨
- => 이행적 종속성이 있다면 안좋은...것.. = 중복

- 중복인 부분을 따로 테이블로 만듦
- 남은 테이블 + author_id 같이 주고
- 중복 테이블의 중복 내용 삭제 * 외래키는 중복 허용
- 이행적종속성이 눈에 보이지 않는 경우
- 같은 성질인 것들은 분명 같은 PK가 있을 것이다...
- 바로 하려는 것보다는 이것이 무엇이다
- 왜 쓰는가 정도를 이해하고 아는 게 중요함.
물리적 데이터 모델링
- 논리적 데이터 모델링이 관계형 데이터베이스 패러다임에 잘 맞는 이상적인 표를 만드는 것이었다면,
- 물리적 데이터 모델링은 선택한 데이터베이스 제품에 만는 현실적인 고려는 하는 방법론
- 제일 중요한 것 -> 성능!
- find slow query 병목이 발생하는 부분 찾기
- 성능을 상향 시키기위한 행위 하기
- 보통 하는 것
- index (읽기 성능 상승 / 쓰기 성능 저하)
- application (cache 저장/데이터베이스 부하 저하)
- denormalization (역정규화 - 표의 구조 바꾸기) : 위의 두가지다 안될 경우..최후의 방법
역정규화 ? Denormalization
- 정규형으로 만든 이상적인 표를 성능이나 개발의 편의성을 위해서 구조를 바꾸는 것
- 쓰기의 편리함을 위해 읽기의 성능을 포기
- 정규화가 성능을 떨어뜨리는 건 아님
1) 하나의 표안에서 컬럼 바꾸기
2) 하나의 표를 여러개로 쪼개기
3) 테이블과 테이블사이의 관계성을 조작해서 지름길 만들기 등등..
👉 역정규화는 규칙이 있는건 아님
엄밀한 공정이 아니라 이러한 게 있다는 샘플..
상황에 맞게 선택하여 하면 됨.
역정규화 1
하나의 표 안에서 컬럼 조작하기 : JOIN을 줄이기

🚨 Join을 하게 되어 성능이 떨어짐

🚩중복을 허용해버림
=> 조인을 하지않아 성능이 좋음
-> 정규화 이전의 문제가 그대로 옴 (중복)
-> 태그 테이블은 또 따로 그대로 있음... (문제)
-> 프로그램이 고장날수도 있지만 역정규화를 하는 이유는 오로지 성능!
역정규화2
컬럼을 조작해서 계산을 줄이기 : 파생 컬럼의 형성 => 계산작업을 줄이기

🚨 Group By 를 하게 되어 성능이 떨어짐

🚩컬럼을 하나 더 추가해줌!
-> Group by 가아니라 select만 해주면됨 (계산작업이 줄어듬)
-> 새로 생성된 칼럼을 계속 유지하기위한 노력을 해줘야 함
역정규화3
표를 쪼개기
대체로 여러 대의 서버로 분산할 때 생각할 수 있는 방법

🚨한 컬럼의 양이 방대하여 성능에 문제가 생기는 경우

🚩컬럼을 기준으로 테이블을 분리
=> 컬럼의 갯수가 적어서 한계가 있음

🚩행을 기준으로 테이블을 분리
=> 한계가 없음..대신 관리가 힘듦
👉 샤딩 : 여러대의 컴퓨터로 스케일 아웃하는 것 : 어려움 (최후의방법)
사용자가 누구냐에 따라서 데이터를 저장하는 서버가 다르게 .. 무한히 많은 처리량 가능
관리가 어려움... 완전 코너에 몰렸을때...
역정규화4
관계의 역정규화 : 관계성을 조작해서 지름길을 만들기 (JOIN을 줄여서 지름길을 만들기)

🚨저자의 태그명과 태그 id를 조회희망

🚩저자 id 를 추가하여 (관계성 추가) join을 줄임
'😺Data Base > 😻 SQLD' 카테고리의 다른 글
| [DB] Transaction - Atomicity 원자성 이해하기 (0) | 2022.09.19 |
|---|---|
| [DB] Index (0) | 2022.09.17 |
| [RDBMS] 관계형 데이터 모델링 1 (0) | 2022.09.14 |
| [DB] 트랜잭션 Transaction 이란? (0) | 2022.09.10 |
| [SQL] 기초 SQL 문법 (0) | 2022.09.08 |