참고한 강의
Index란?
- 색인
- 쉽게 찾아 볼수 있도록 일정한 순서에 따라 놓은 목록
- > 원하는 값을 빠르게 찾는다!
- 👉SELECT에 활용 가능!
Database Index

- 대용량데이터에서 조회를 할때 순차적으로 확인을 하면 매우 느림 (기준없이 되어있기때문)
- 데이터가 특정 기준으로 정렬되어 있다면 검색을 빠르게 할 수 있다!
- = 인덱스를 정한 경우 👉 빠르게 찾을 수 있음!

🚩 인덱스란 데이터베이스 테이블에 대한 검색성능을 향상시키는 자료구조이며 WHERE 절 등을 통해 활용된다
- 인덱스의 특징
- 항상 최신의 정렬상태를 유지
- 인덱스도 하나의 데이터베이스 객체
- 데이터 베이스 크기의 약 10% 정도의 저장공간 필요
Index Algorithm
- 용어정리
- 페이지 : 데이터가 저장되는 단위
- 풀 테이블 스캔 : 순차적으로 처음부터 끝까지 조회
- 특징 : 순차적으로 접근 , 접근 비용이 감소
- 사용
- 적용 가능한 인덱스가 없는 경우
- 인덱스 처리 범위가 넓은 경우
- 크기가 작은 테이블에 엑세스 하는 경우
- Binaty Search Tree (이진 탐색 트리) - 시간복잡도?
- 이진탐색 + 연결리스트의 장점
- 균형없는 이진 탐색 트리의 단점을 극복하기 위해서 나온 것(=>B TREE)
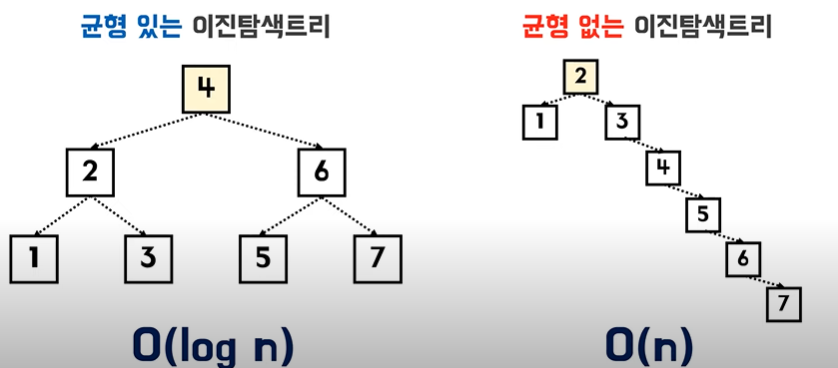
- B Tree (Balanced-Tree)
- 트리 높이가 같음
- 자식 노드를 2개 이상 가질 수 있음
- 기본 데이터베이스 인덱스 구조

🚩 비트리 적용 안되었을 때 조회
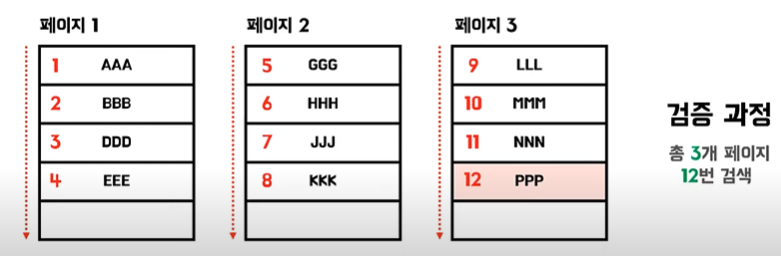
👉비트리 적용 시 조회

🚩 비트리 적용시 성능이 향상!
❓❓ SELECT 뿐 만 아니라 INSERT / UPDATE / DELETE 도 성능이 좋아질까?
Insert
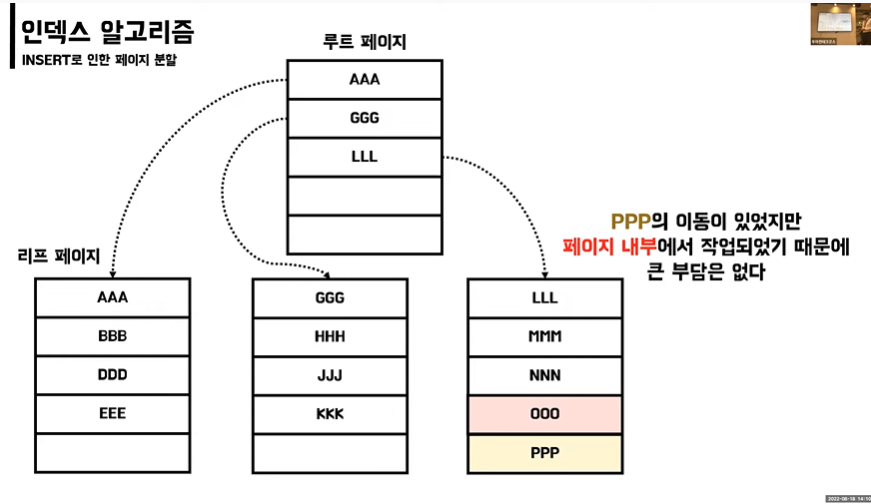
👉페이지 내부의 작업시에는 부담이 없음
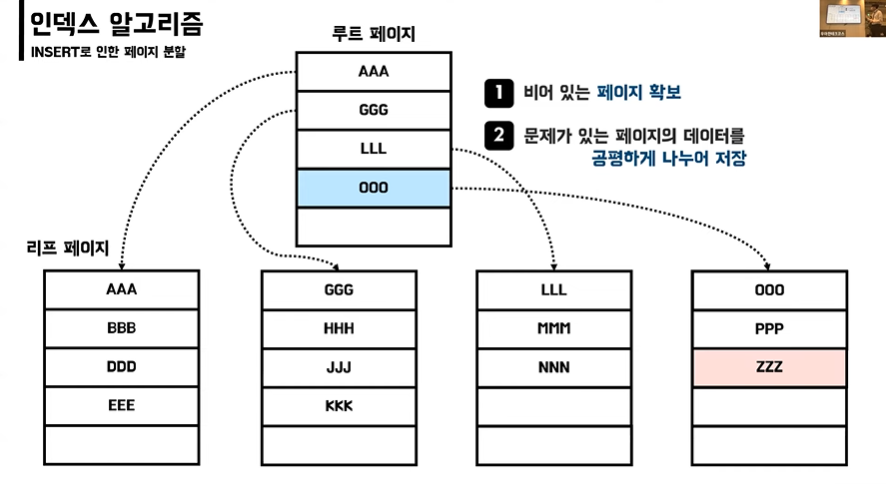
🚨페이지 분할이 필요한 경우!
- 페이지에 새로운 데이터를 추가할 여유공간이 없어 페이지에 변화가 발생
- DB가 느려지고 성능에 영향을 준다
DELETE
- 인덱스의 데이터를 실제로 지우지 않고 사용안함 표시를 한다
UPDATE
update가 따로 되는 게 아니고 두가지 작업을 거친다
- DELETE (기존 값 사용안함 표시)
- INSERT (변경된 값 삽입)
🚩 UPDATE & DELETE😏❗
=> WHERE 절로 처리할 대상을 찾기 위한 조회 성능은 향상되나
- 사용하지 않는 인덱스가 적용되었다면 불필요한 처리량 증가
- 사용안함 표시로 페이지 낭비 및 인덱스 조각화 심해짐

INDEX의 종류
- 용어 정리
- 클러스터 : 무리, 군집, 무리를 이루다

클러스터링 인덱스
- 실제 데이터와 같은 무리의 인덱스 (사전 인덱스)


👉 클러스터링 인덱스 적용 방법

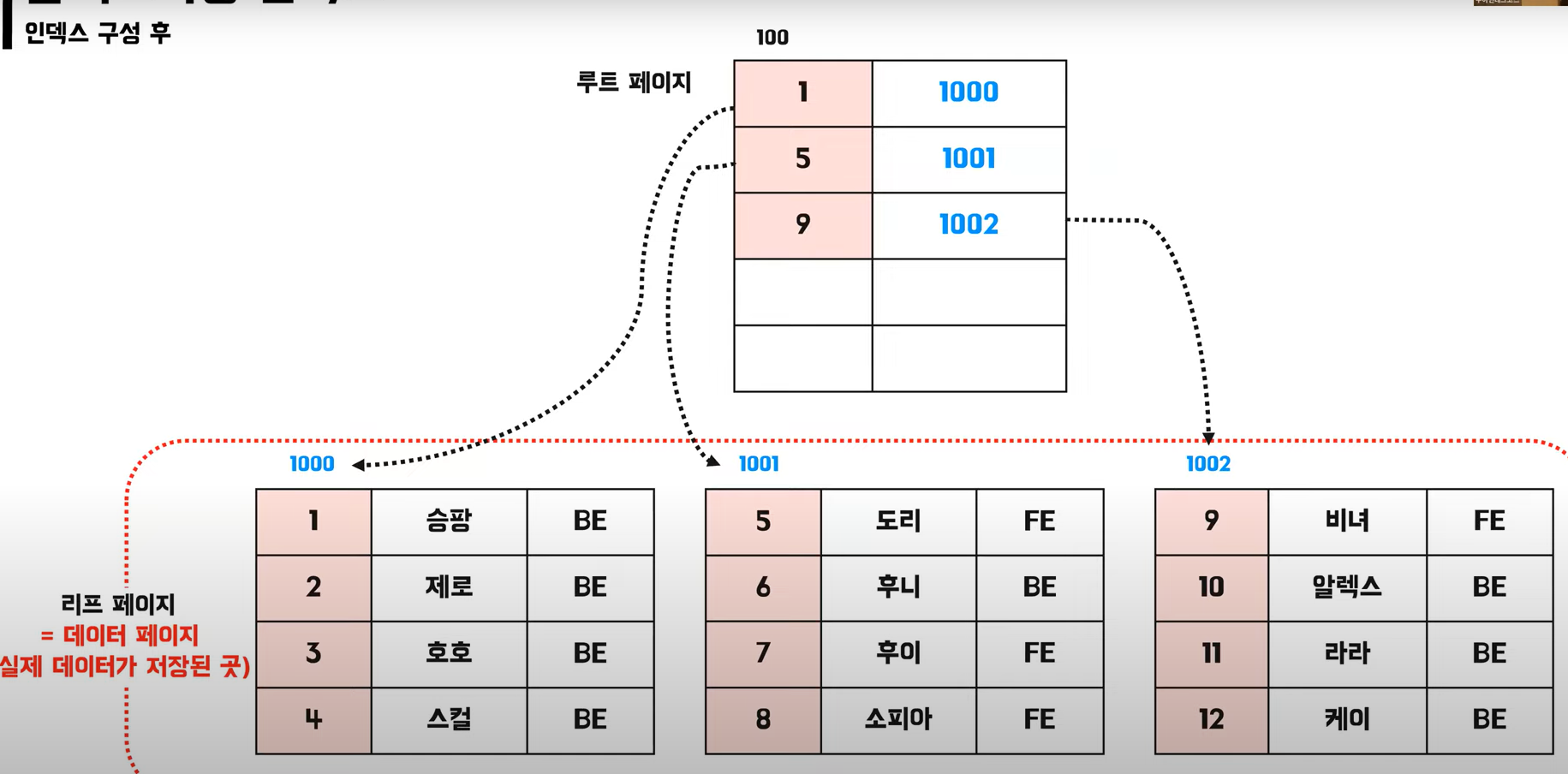
👉 클러스터링 인덱스 적용 후 비트리 구조
❓1000 ? : 데이터페이지의 주소
❓데이터 페이지 : 실제 데이터가 저장되는 페이지 = 리프 페이지
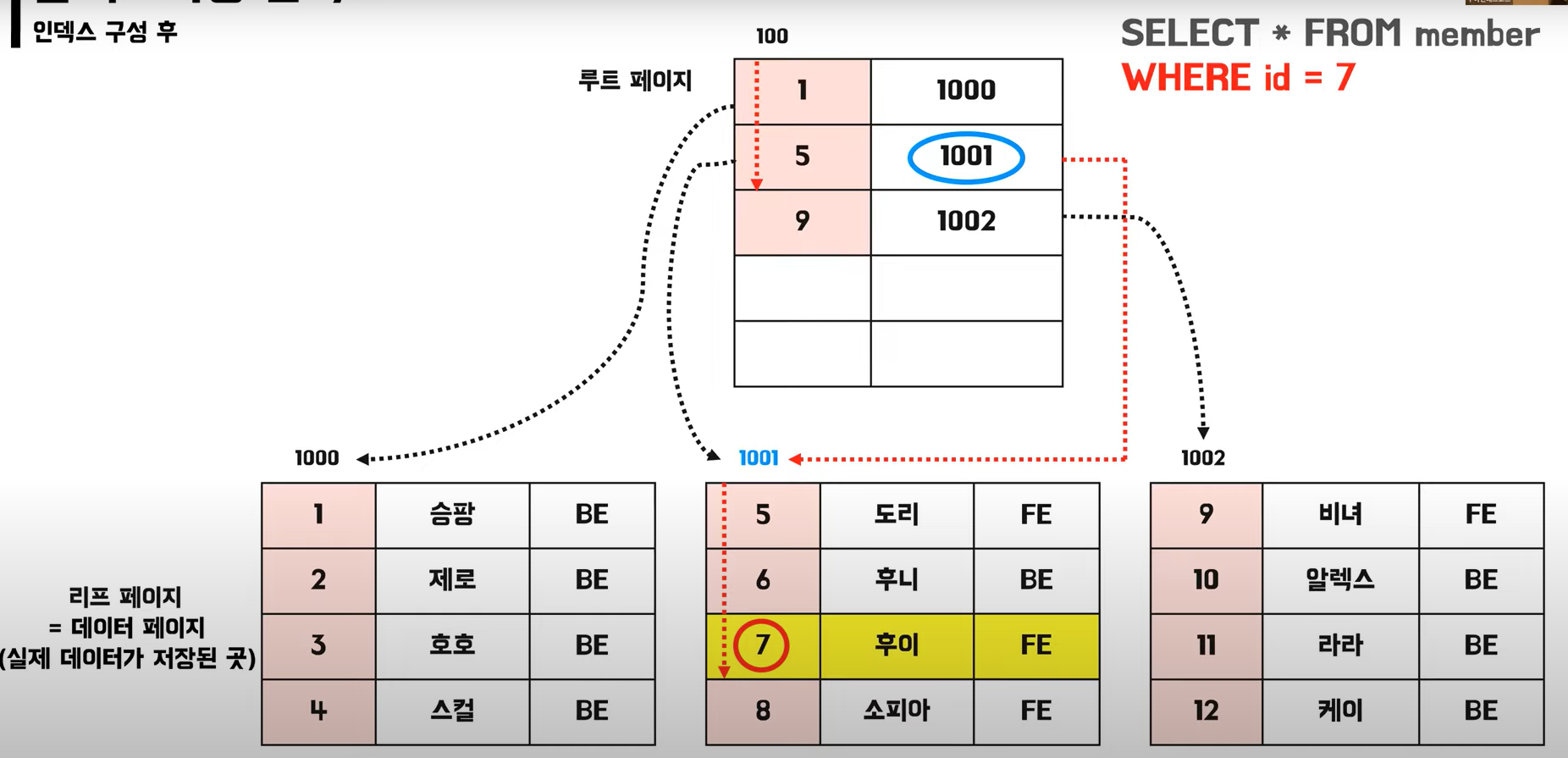
🚩 클러스터링 인덱스 적용 시 조회
👉 클러스터링 인덱스의 특징
- 실제 데이터 자체가 정렬
- 테이블 당 1개만 존재 가능
- 리프 페이지가 데이터 페이지
- 아래의 제약조건 시 자동 생성
- Primary key(우선순위)
- unique + not null
논클러스터링 인덱스 (=보조 인덱스, 세컨더리 인덱스)
- 실제 데이터와 다른 무리의 별도의 인덱스 (책 찾아보기 페이지)
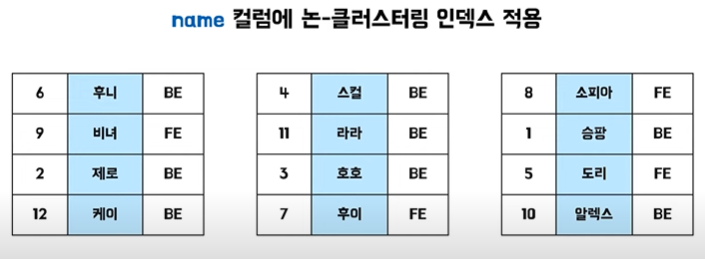

👉 논클러스터링 인덱스 적용 방법
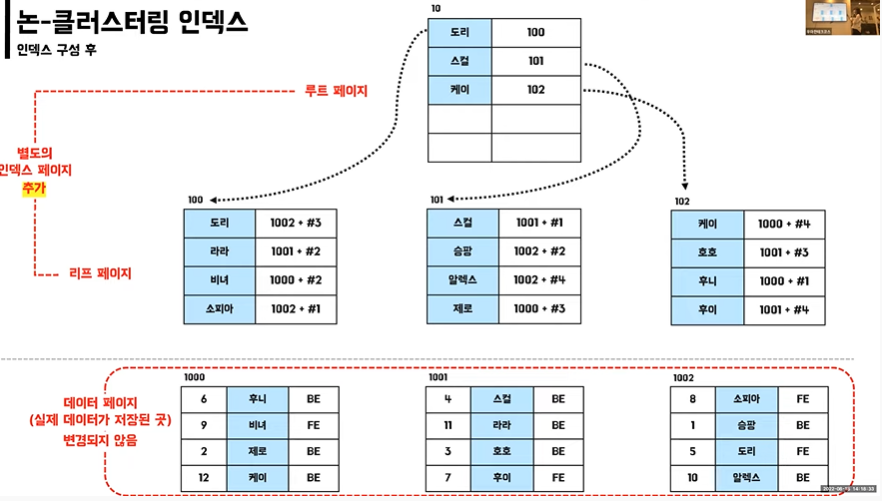
👉 논클러스터링 인덱스 적용 후 비트리 구조
❓1002 #3
=> 1002 데이터 페이지 주소 / #3 : 3번째 값
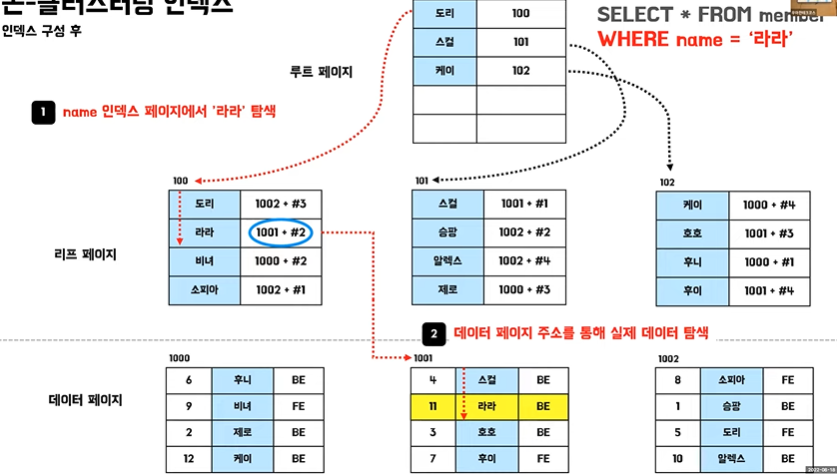
👉 논클러스터링 인덱스의 특징
- 실제 데이터 페이지는 그대로
- 별도의 인덱스 페이지 생성 ->추가 공간 필요
- 테이블당 여러개 존재
- 리프페이지에 실제 데이터 페이지 주소를 담고 있음
- unique 제약조건 적용시 자동 생성
- 직접 index 생성시 논클러스터링 인덱스 생성
❓❓ 클러스터링 + 논클러스터링 인덱스를 함께 적용하면 어떨까?
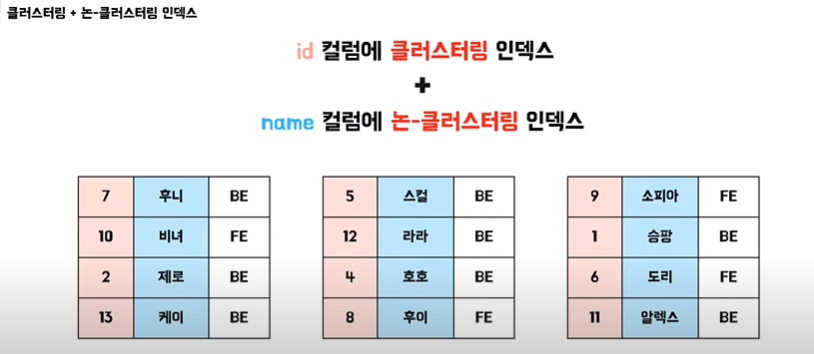


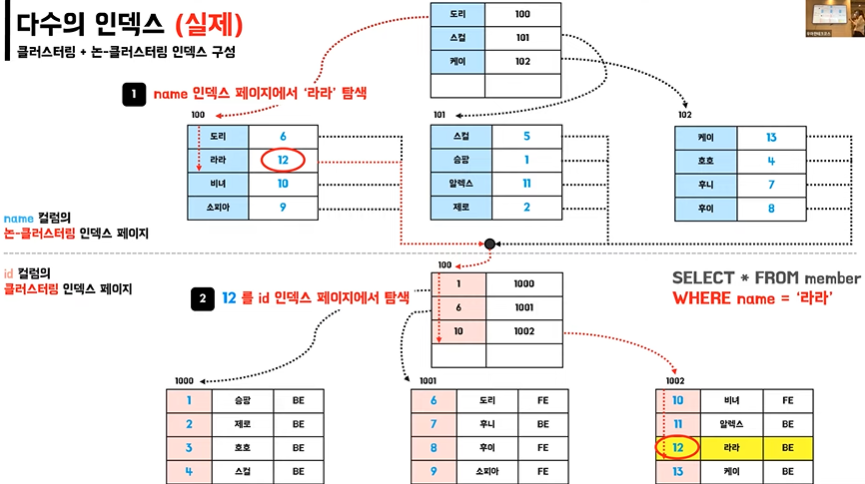
👉 다수의 인덱스 구성 시 조회 방법
❓ 왜 예상과 다르게 name 컬럼 인덱스 페이지에 데이터 페이지 주소가 들어가지 않고 클러스터링 인덱스 컬럼의 실제값이 들어갈까?

🚩Insert를 할때 페이지 분할이 발생하여 주소변경을 해야하기 때문 !(불필요한 작업!)

인덱스의 적용 기준?
- Cardinality 카디널리티 : 그룹 내 요소의 개수

- 카디널리티(그룹 내 요소의 개수)가 높은 것 = 중복 수치가 낮은 것!
ex) id email 주민번호
🚩 인덱스 적용가능한 칼럼은?
- 카디널리티가 높은 (중복도가 낮은) 컬럼
- WHERE, JOIN, ORDER BY 절에 자주 사용되는 컬럼
- 인덱스는 추가 공간이 필요로 된다
- 조건 절이 없다면 인덱스가 사용되지 않는다 - 인서트 / 업데이트 / 딜리트가 자주 발생하지 않는 컬럼
- 규모가 작지 않은 테이블
🚨인덱스 적용 시 주의사항🚨
- 잘 활용되지 않는 인덱스는 과감히 제거하자
- WHERE 절에 사용되더라도 자주 사용해야 가치가 있다
- 불필요한 인덱스로 성능저하가 발생할 수 있다면 - 데이터 중복도가 높은 컬럼은 인덱스 효과가 적다
- 자주 사용되더라도 인서트/ 업데이트/ 딜리트가 자주 일어나는지 고려해야 한다
- 일반적인 웹 서비스와 같은 온라인 트랜잭션 환경에서 쓰기와 읽기 비율은 2:8 또는 1:9이다
- 조금 느린 쓰기를 감수하고 빠른 읽기를 선택하는 것도 하나의 방법이다
https://herojoon-dev.tistory.com/142
JPA Table에 Index 설정하기
목표 JPA Table에 Index 설정하기 단일 Index 지정 복합 Index 지정 Unique Index 지정 환경 Framework : Spring Boot 2.6.7 Build : Gradle 6.9.2 JDK : JDK11 해보기 ● Index 추가 전 JPA Entity ● Index 추..
herojoon-dev.tistory.com
'😺Data Base > 😻 SQLD' 카테고리의 다른 글
| [DB] Transaction - 동시성 문제 (0) | 2022.09.20 |
|---|---|
| [DB] Transaction - Atomicity 원자성 이해하기 (0) | 2022.09.19 |
| [RDBMS] 관계형 데이터 모델링 2 (0) | 2022.09.16 |
| [RDBMS] 관계형 데이터 모델링 1 (0) | 2022.09.14 |
| [DB] 트랜잭션 Transaction 이란? (0) | 2022.09.10 |